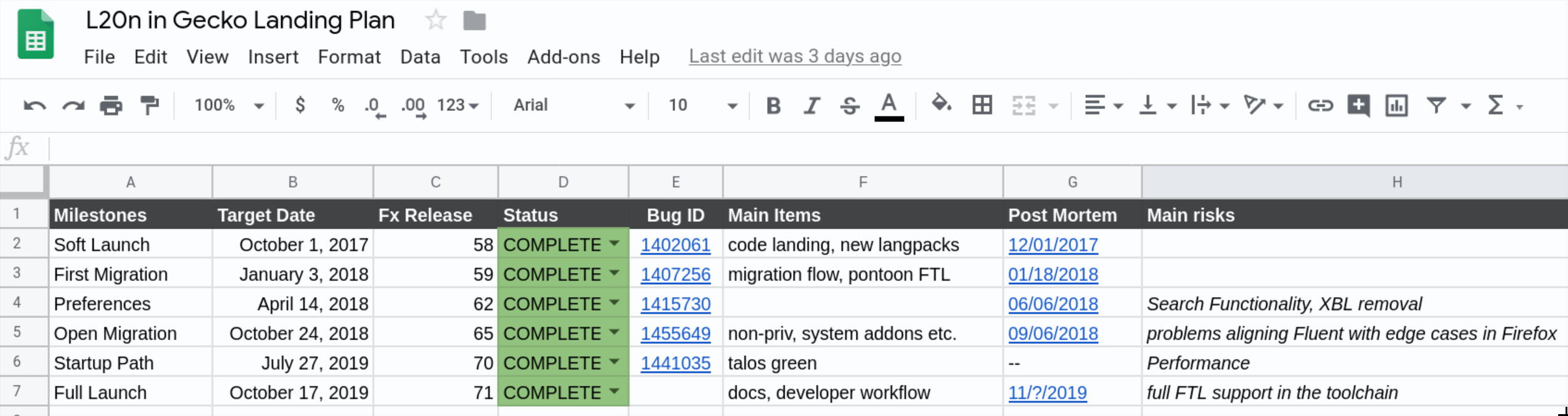
After nearly 3 years of work, 13 Firefox releases, 6 milestones and a lot of bits flipped, I’m happy to announce that the project of integrating the Fluent Localization System into Firefox is now completed!
It means that we consider Fluent to be well integrated into Gecko and ready to be used as the primary localization system for Firefox!
Below is a story of how that happened.
3 years of history
At Mozilla All-Hands in December 2016 my team at the time (L10n Drivers) presented a proposal for a new localization system for Firefox and Gecko – Fluent (code name at the time – “L20n“).
The proposal was sound, but at the time the organization was crystallizing vision for what later became known as Firefox Quantum and couldn’t afford pulling additional people in to make the required transition or risk the stability of Firefox during the push for Quantum.
Instead, we developed a plan to spend the Quantum release cycle bringing Fluent to 1.0, modernizing the Internationalization stack in Gecko, getting everything ready in place, and then, once the Quantum release completes, we’ll be ready to just land Fluent into Firefox!
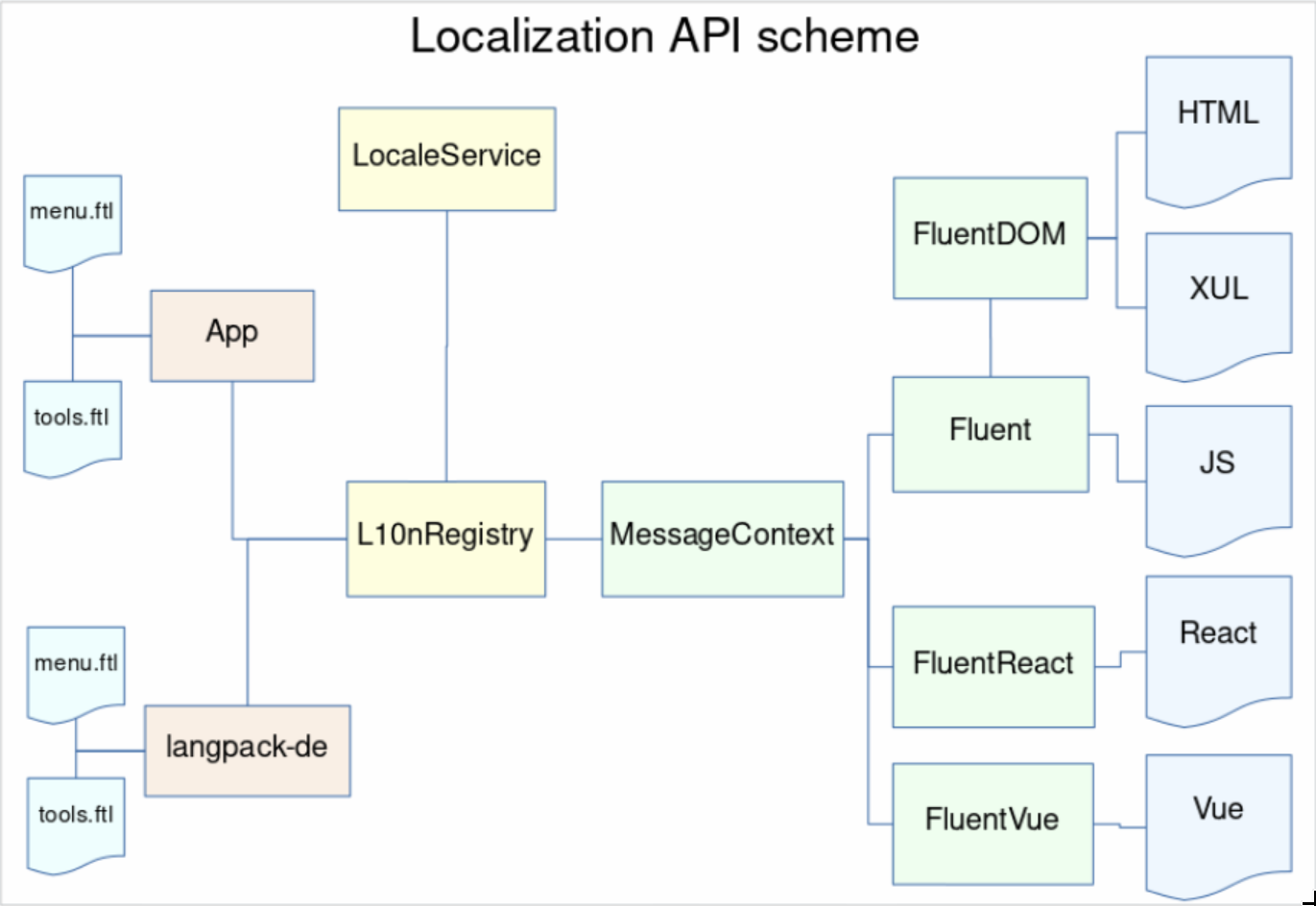
We divided the work between two main engineers on the project – Staś Małolepszy took the lead of Fluent itself, while I became responsible for integrating it into Firefox.
My initial task was to refactor all of the locale management and higher-level internationalization integration (date/time formatting, number formatting, plural rules etc.) to unify around a common Unicode-backed model, all while avoiding any disruptions for the Quantum project, and by all means avoid any regressions.
I documented the first half of 2017 progress in a blog post “Multilingual Gecko in 2017” which became a series of reports on the progress of in our internationalization module, and ended up with a summary about the whole rearchitecture which ended up with a rewrite of 90% of code in intl::locale component.
Around May 2017, we had ICU enabled in all builds, all the required APIs including unified mozilla::intl::LocaleService, and the time has come to plan how we’re going to integrate Fluent into Gecko.
Planning
Measuring
Before we began, we wanted to understand what the success means, and how we’re going to measure the progress.
Stating that we aim at making Fluent a full replacement for the previous localization systems in Firefox (DTD and .properties) may be overwhelming. The path from landing the new API in Gecko, to having all of our UI migrated would likely take years and many engineers, and without a good way to measure our progress, we’d be unable to evaluate it.
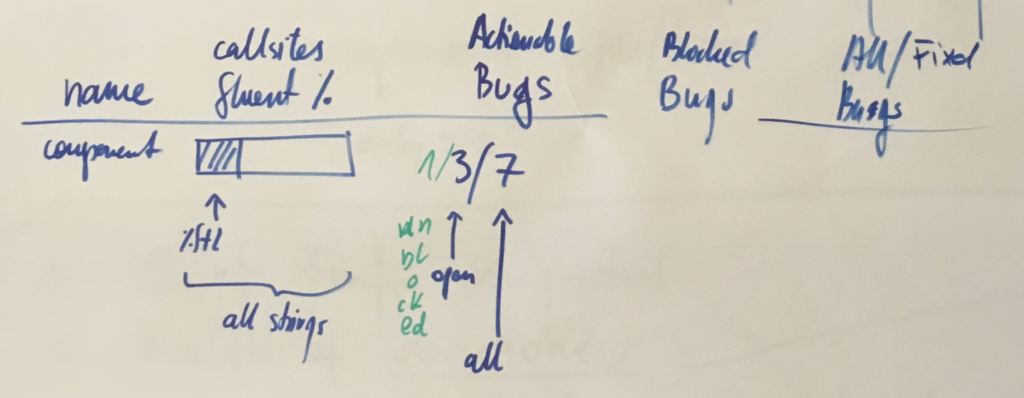
Together with Axel, Staś and Francesco, we spent a couple days in Berlin going back and forth on what should we measure. After brainstorming through ideas such as fluent-per-component, fluent-per-XUL-widget and so on, we eventually settled on the simplest one – percentage of localization messages that use Fluent.
We knew we could answer more questions with more detailed breakdowns, but each additional metric required additional work to receive it and keep it up to date. With limited resources, we slowly gave up on aiming for detail, and focused on the big picture.
Getting the raw percentage of strings in Fluent to start with, and then adding more details, allowed us to get the measurements up quickly and have them available independently of further additions. Big picture first.
Staś took ownership over the measuring dashboard, wrote the code and the UI and soon after we had https://www.arewefluentyet.com running!
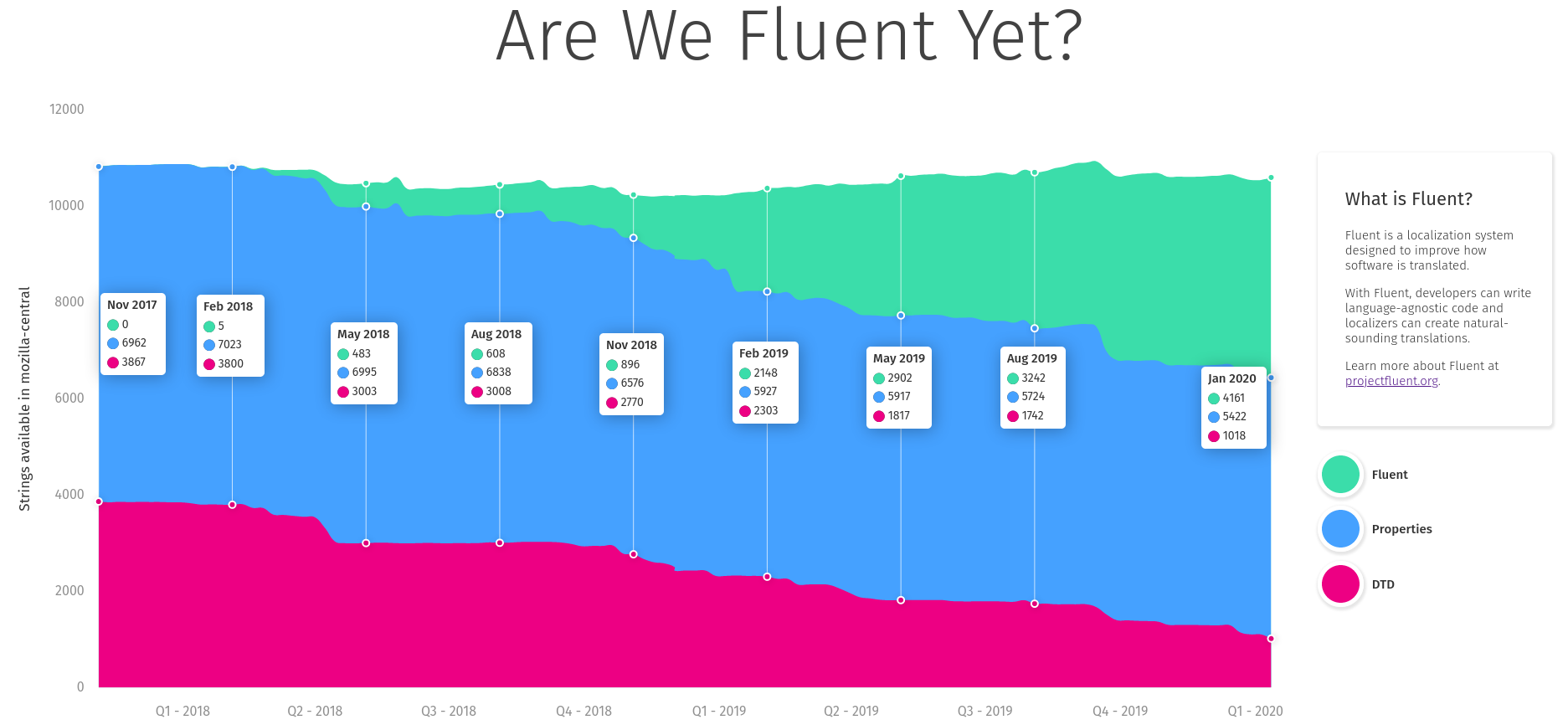
Later, with the help from Eric Pang, we were able to improve the design and I added two more specific milestones: Main UI, and Startup Path.
The dashboard is immensely useful, both for monitoring the progress, and evangelizing the effort, and today if you visit any Mozilla office around the World, you’ll see it cycle through on the screens in common areas!
Target Component
To begin, we needed to get agreement with the Firefox Product Team on the intended change to their codebase, and select a target for the initial migration to validate the new technology.
We had a call with the Firefox Product Lead who advised that we start with migrating Preferences UI as a non-startup, self-contained, but sufficiently large piece of UI.
It felt like the right scale. Not starting with the startup path limited the risk of breaking peoples Nightly builds, and the UI itself is complex enough to test Fluent against large chunks of text, giving our team and the Firefox engineers time to verify that the API works as expected.
We knew the main target will be Preferences now, but we couldn’t yet just start migrating all of it. We needed smaller steps to validate the whole ecosystem is ready for Fluent, and we needed to plan separate steps to enable Fluent everywhere.
I split the whole project into 6 phases, each one gradually building on top of the previous ones.