2020 is shaping up to be an amazing year for JavaScript Internationalization API.
After many years of careful design we’re seeing a lot of the work now coming close to completion with a number of high profile APIs on track for inclusion in ECMAScript 2020 standard!
What’s coming up?
Let’s cut to the chase. Here’s the list of APIs coming to the JavaScript environment of your choice:
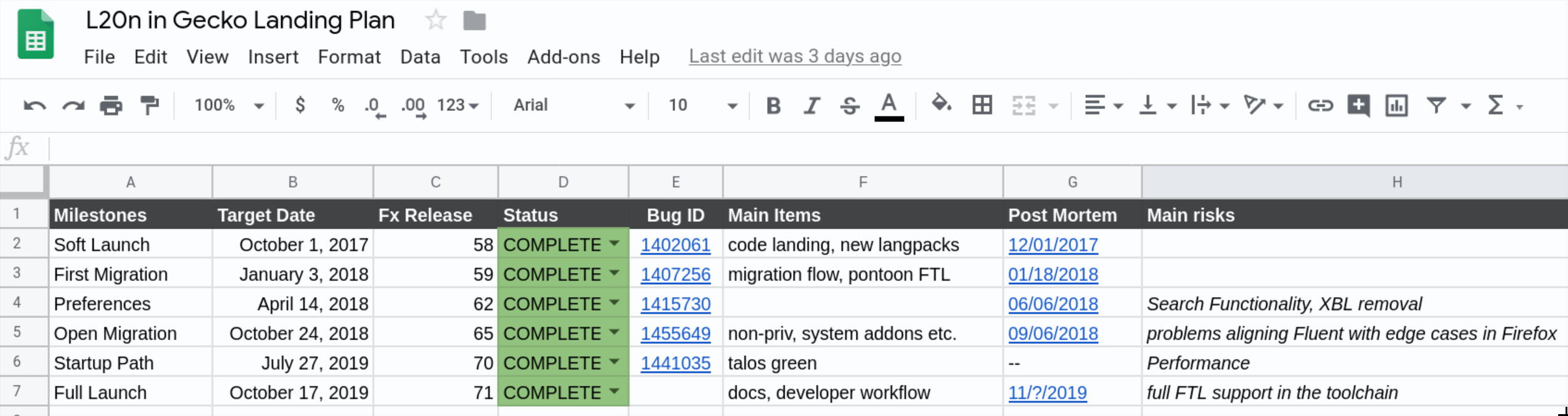
After nearly 3 years of work, 13 Firefox releases, 6 milestones and a lot of bits flipped, I’m happy to announce that the project of integrating the Fluent Localization System into Firefox is now completed!
It means that we consider Fluent to be well integrated into Gecko and ready to be used as the primary localization system for Firefox!
The proposal was sound, but at the time the organization was crystallizing vision for what later became known as Firefox Quantum and couldn’t afford pulling additional people in to make the required transition or risk the stability of Firefox during the push for Quantum.
Instead, we developed a plan to spend the Quantum release cycle bringing Fluent to 1.0, modernizing the Internationalization stack in Gecko, getting everything ready in place, and then, once the Quantum release completes, we’ll be ready to just land Fluent into Firefox!
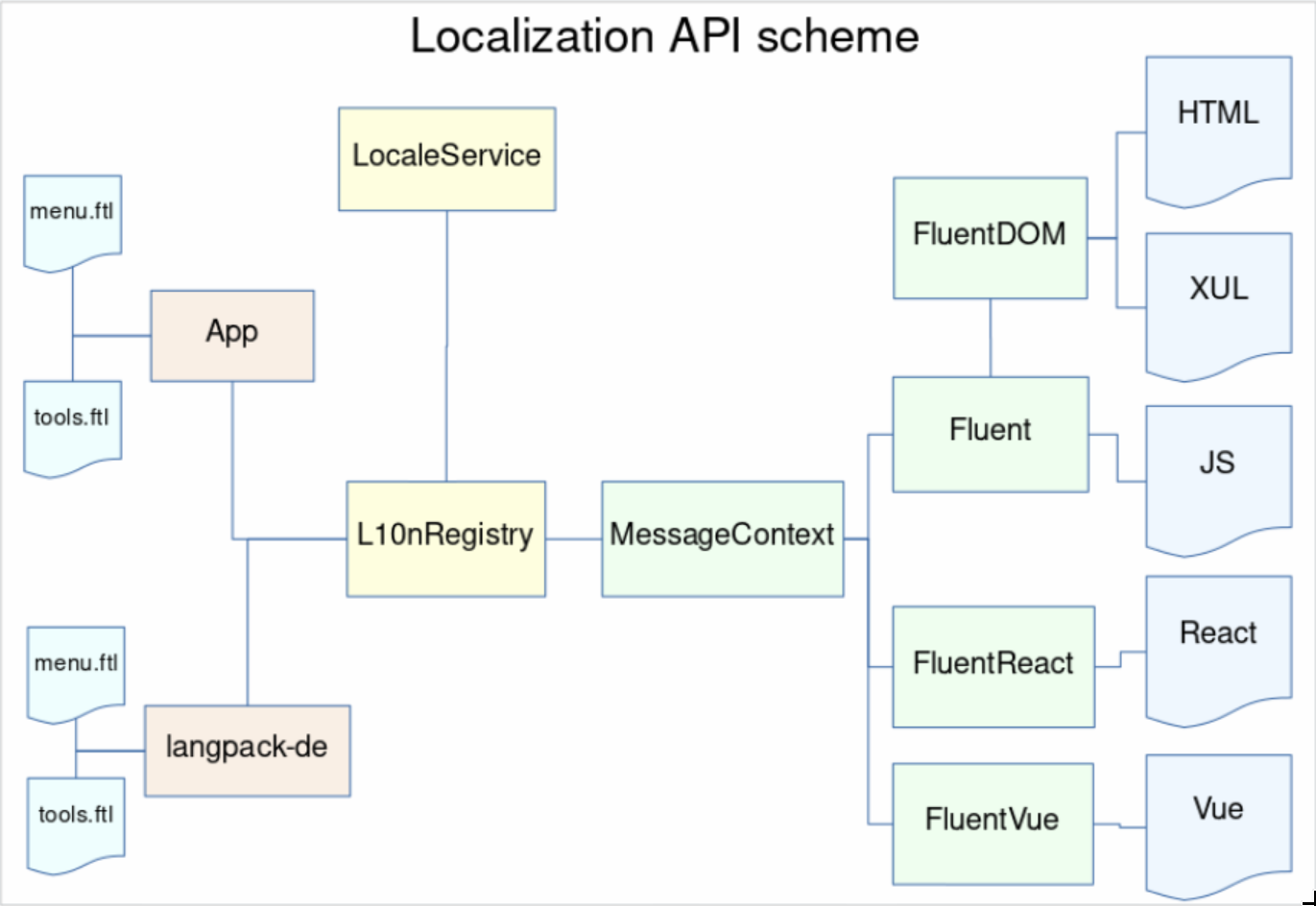
Original schema of the proposed system integration into Gecko
We divided the work between two main engineers on the project – Staś Małolepszy took the lead of Fluent itself, while I became responsible for integrating it into Firefox.
My initial task was to refactor all of the locale management and higher-level internationalization integration (date/time formatting, number formatting, plural rules etc.) to unify around a common Unicode-backed model, all while avoiding any disruptions for the Quantum project, and by all means avoid any regressions.
I documented the first half of 2017 progress in a blog post “Multilingual Gecko in 2017” which becamea series of reports on the progress of in our internationalization module, and ended up with a summary about the whole rearchitecture which ended up with a rewrite of 90% of code in intl::locale component.
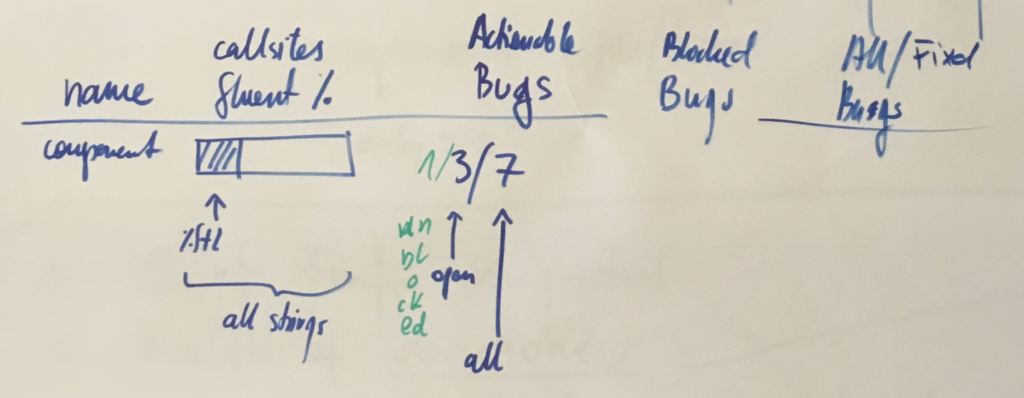
Before we began, we wanted to understand what the success means, and how we’re going to measure the progress.
Stating that we aim at making Fluent a full replacement for the previous localization systems in Firefox (DTD and .properties) may be overwhelming. The path from landing the new API in Gecko, to having all of our UI migrated would likely take years and many engineers, and without a good way to measure our progress, we’d be unable to evaluate it.
Original draft of a per-component dashboard
Together with Axel, Staś and Francesco, we spent a couple days in Berlin going back and forth on what should we measure. After brainstorming through ideas such as fluent-per-component, fluent-per-XUL-widget and so on, we eventually settled on the simplest one – percentage of localization messages that use Fluent.
Original draft of a global percentage view
We knew we could answer more questions with more detailed breakdowns, but each additional metric required additional work to receive it and keep it up to date. With limited resources, we slowly gave up on aiming for detail, and focused on the big picture.
Getting the raw percentage of strings in Fluent to start with, and then adding more details, allowed us to get the measurements up quickly and have them available independently of further additions. Big picture first.
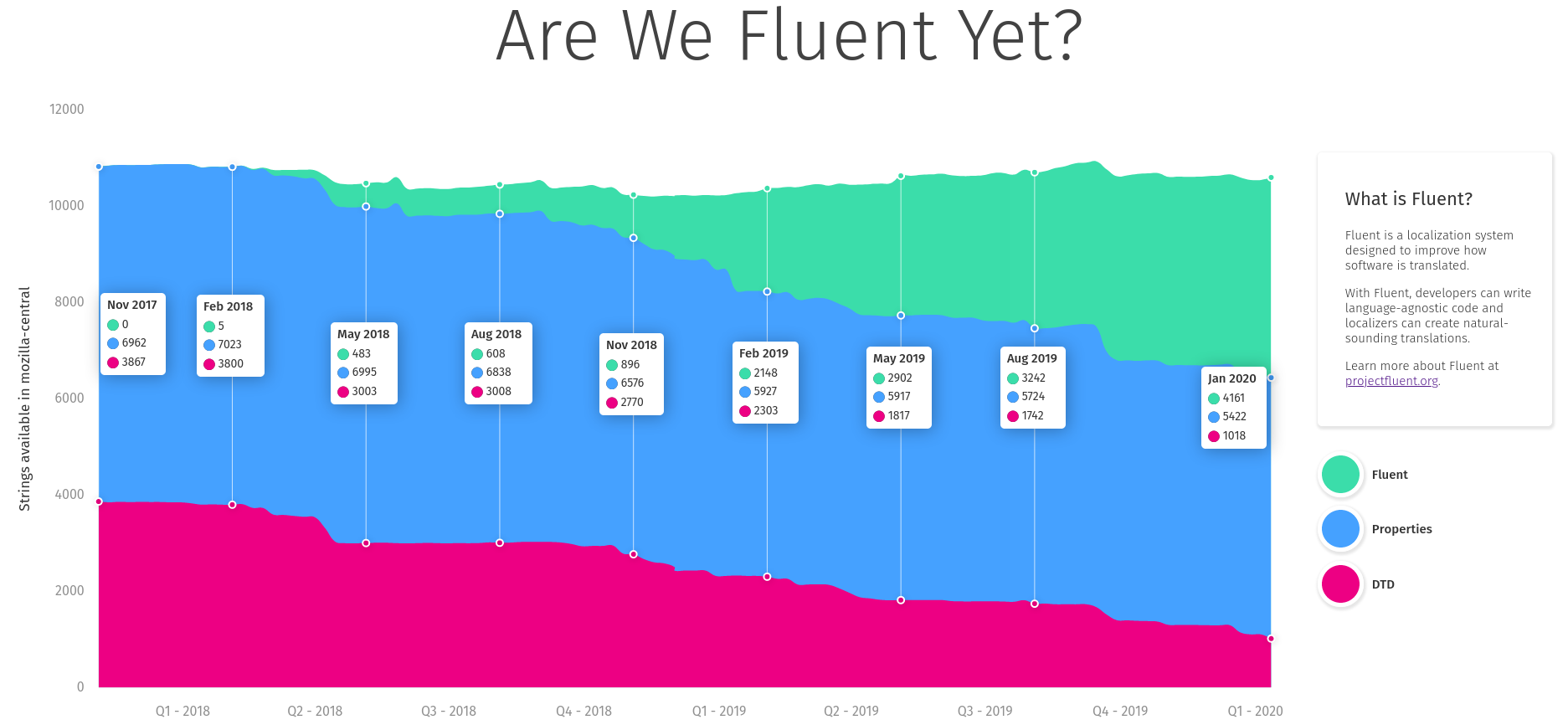
Staś took ownership over the measuring dashboard, wrote the code and the UI and soon after we had https://www.arewefluentyet.com running!
AreWeFluentYet.com as of January 12th 2020
Later, with the help from Eric Pang, we were able to improve the design and I added two more specific milestones: Main UI, and Startup Path.
The dashboard is immensely useful, both for monitoring the progress, and evangelizing the effort, and today if you visit any Mozilla office around the World, you’ll see it cycle through on the screens in common areas!
Target Component
To begin, we needed to get agreement with the Firefox Product Team on the intended change to their codebase, and select a target for the initial migration to validate the new technology.
We had a call with the Firefox Product Lead who advised that we start with migrating Preferences UI as a non-startup, self-contained, but sufficiently large piece of UI.
It felt like the right scale. Not starting with the startup path limited the risk of breaking peoples Nightly builds, and the UI itself is complex enough to test Fluent against large chunks of text, giving our team and the Firefox engineers time to verify that the API works as expected.
We knew the main target will be Preferences now, but we couldn’t yet just start migrating all of it. We needed smaller steps to validate the whole ecosystem is ready for Fluent, and we needed to plan separate steps to enable Fluent everywhere.
I split the whole project into 6 phases, each one gradually building on top of the previous ones.
Outline of the phases used by the stakeholders to track progress
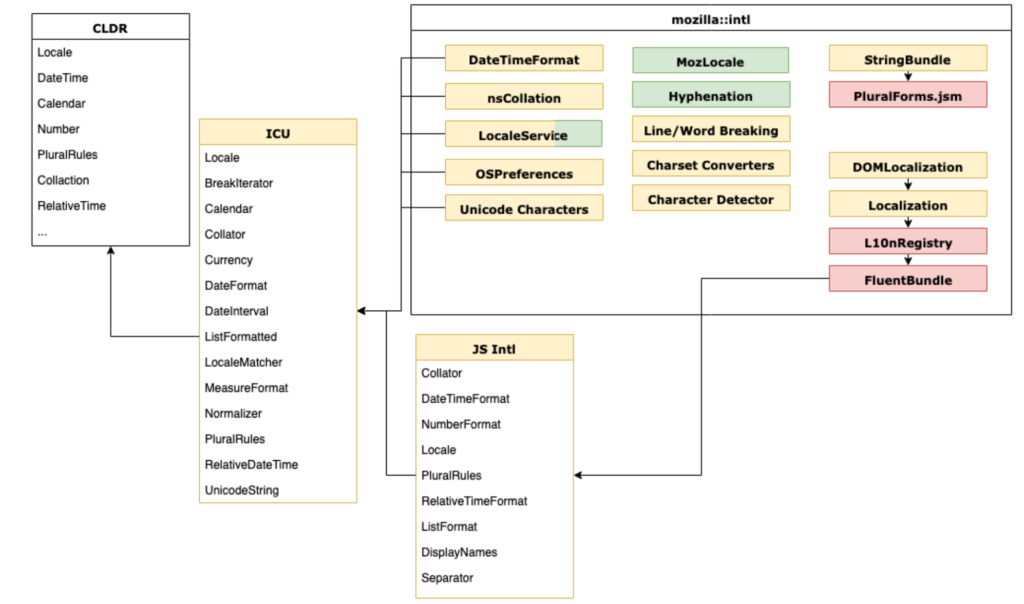
Between 2017 and 2018 we refactored a major component of the Gecko Platform – the intl/locale module. The main motivator was the vision of Multilingual Gecko which I documented in a blog post.
Firefox 65 brought the first major user-facing change that results from that refactor in form of Locale Selection. It’s a good time to look back at the scale of changes. This post is about the refactor of the whole module which enabled many of the changes that we were able to land in 2019 to Firefox.
All of that work led to the following architecture:
Intl module in Gecko as of Firefox 72 Yellow – C++, Red – JavaScript, Green – Rust
Evolution vs Revolution
It’s very rare in software engineering that projects of scale (a Gecko module with close to 500 000 lines of code) go through such a major transition. We’ve done it a couple times, with Stylo, WebRender etc., but each case is profound, unique and rare.
There are good reasons not to touch an old code, and there are good reasons against rewriting such a large pile of code.
There’s not a lot of accrued organizational knowledge about how to handle such transitions, what common pitfalls await, and how to handle them.
That makes it even more unique to realize how smooth this change was. We started 2017 with a vision of putting a modern localization system into Firefox, and a platform that required a substantial refactor to get there.
To give you a rough idea on the scope of changes – only 10% of ./intl/locale directory remained the same between Firefox 51 and 65!
In 2018, we started building on top of it, witnessing a reduced amount of complex work on the lower level, and much higher velocity of higher level changes with three overarching themes:
Migrate Firefox to Fluent
Improve Firefox locale management and multilingual use cases
Upstream all of what we can to be part of the Web Platform
What’s amazing to me, is that we avoided any major architectural regression in this transition. We didn’t have to revisit, remodel, revert or otherwise rethink in any substantial way any of the new APIs! All of the work, as you can see above, was put into incremental updates, deprecation of old code, standardization and integration of the new. Everything we designed to handle Firefox UI that has been proposed for standardization has been accepted, in roughly that form, by our partners from ECMA TC39 committee, and no major assumption ended up being wrong.
I believe that the reason for that success is the slow pace we took (a year of time to refactor, a year to stabilize), support from the whole organization, good test coverage and some luck.
On December 26th 2016 I filed a bug titled “Unify locale selection across components and languages“. Inside it, you can find a long list of user scenarios which we dared to tackle and which, at the time, felt completely impossible to provide.
Two years later, we had the technical means to address the majority of the scenarios listed in that bug.
Three new centralized components played a crucial role in enabling that:
LocaleService
LocaleService was the first new API. At the time, Firefox locale management was decentralized. Multiple components would try to negotiate languages for their own needs – UI chrome API, character detection, layout etc.
They would sometimes consult nsILocaleService /nsILocale which were shaped after the POSIX model and allowed to retrieve the locale based on environmental, per-OS, variables.
There was also a set of user preferences such as general.useragent.locale and intl.locale.matchOS which some of the components took into account, and others ignored.
Finally, when a locale was selected, the UI would use OS specific calls to perform internationalization operations which depended on what locale data and what intl APIs were available in the platform.
The result was that our UI could easily become inconsistent, jumping between POSIX variables, user settings, and OS settings, leading to platform-specific bugs and users stuck in a weird mid-air state with their UI being half in one locale, and half in the other.
The role of the new LocaleService was to unify that selection, provide a singleton service which will manage locale selection, negotiation and interaction with platform-specific settings.
LocaleService was written in C++ (I didn’t know Rust at the time), and quickly started replacing all hooks around the platform. It brought four major concepts:
All APIs accepted and returned fallback lists, rather than a single locale
All APIs manage their state through runtime negotiation
Events were fired to notify users on locale changes
The result, combined with the introduction of IPC for LocaleService, led us in the direction of cleaner system that maintains its state and can be reasoned about.
In the process, we kept extending LocaleService to provide the lists of locales that we should have in Gecko, both getters and setters, while maintaining the single source of truth and event driven model for reacting to runtime locale changes.
That allowed us to make our codebase ready for, first locale selection, and then runtime locale switching, that Fluent was about to make possible.
With the centralization of internationalization API around our custom ICU/CLDR instance, we needed a new layer to handle interactions with the host environment. This layer has been carved out of the old nsILocaleService to facilitate learning user preferences set in Windows, MacOS, Gnome and Android.
It has been a fun ride with incremental improvements to handle OS-specific customizations and feed them into LocaleService and mozIntl, but we were able to accomplish the vast majority of the goals with minimum friction and now have a sane model to reason about and extend as we need.
With LocaleService and OSPreferences in place we had all the foundation we needed to negotiate a different set of locales and customize many of the intl formatters, but we didn’t have a way to separate what we expose to the Web from what we use internally.
We needed a wrapper that would allow us to use the JS Intl API, but with some customizations and extensions that are either not yet part of the web standard, or, due to fingerprinting, cannot be exposed to the Web.
We developed `mozIntl` to close that gap. It exposes some bits that are internal only, or too early for external adoption, but ready for the internal one.
mozIntl is pretty stable now, with a few open bugs, 96% test coverage and a lot of its functionality is now in the pipeline to become part of ECMA402. In the future we hope this will make mozIntl thinner.
2019
In 2019, we were able to focus on the migration of Firefox to Fluent. That required us to resolve a couple more roadblocks, like startup performance and caching, and allowed us to start looking into the flexibility that Fluent gives to revisit our distribution channels, build system models and enable Gecko based applications to handle multilingual input.
Gecko is, as of today, a powerful software platform with a great internationalization component leading the way in advancing Web Standards and fulfilling the Mozilla mission by making the Web more accessible and multilingual. It’s a great moment to celebrate this achievement and commit to maintain that status.
Welcome to the third edition of Multilingual Gecko Status Update!
In the previous update we covered the work which landed in Firefox 59 and Firefox 60.
At the time, we’ve been finalizing the platform work to support Fluent localization system, and we were in the middle of migration of the first Firefox UI component – Preferences – to it.
Today, we’ll pick up right where we left off!
Firefox 61 (June)
Firefox 61 fits into the trend of things calming down in Intl – and it’s a great news! It means that we are reaching platform maturity after all the groundbreaking refactors in 2017, and we all can focus on the work on top of the modules, rather than playing whack-a-mole fixing bugs and adding missing features.
The former gave us a stable unified API for presenting relative time (such as “In 5 minutes” or “10 days ago”) while the latter unified how we present language, region and combinations of those in our user interface based on the Unicode CLDR representation (example: “English (United States)”).
As I explained in my earliest posts, one of the things I’m particularly proud of is that we go the extra mile to use every such opportunity to not only fix the immediate Firefox UI need, but also push such proposals for standardization and in result make the Web Platform more complete.
The documentation has been insanely useful in distributing knowledge and helping engineers feel more comfortable working with the new stack, and I’m very happy we reached a stage where landing a documentation is the big news 🙂
In the Fluent land we spent the March-May timeframe moving from a 100 messages to 500 Fluent messages in Firefox!
This cycle was quite similar to the previous one, with a bulk of work going into regular maintenance and cleanups.
For my work, the trend is to start integrating Fluent deeper into Gecko with more work around L10nRegistry v1 limitations and getting deeper DOM integration to improve XUL performance.
In this cycle I landed a XPCOM mozIDOMLocalization API which allows us to call Fluent from C++ and was required for a bigger change that we landed in Firefox 64.
One new theme is Kris Maglione who started working onreducing the performanceand memoryoverhead coming from the old StringBundle API (used for .properties). With all the new work centralized around Fluent, but with a large portion of our strings still using StringBundle, it becomes a great target for optimizations by cutting out everything we don’t use and now we know – we never will.
This release, is still getting stabilized and will get released in December, but the work cycle on it happened between September and October, so I can already provide you an account of that work!
Besides of a regular stack of cleanups coming from Henri and me, we’ve seen Ehsan Akhgari taking over from Kris to remove morelines of unused code.
The really big change was the introduction of DocumentL10n API which is a C++ API with its own WebIDL tightly integrated into the very core of DOM module in Gecko – nsIDocument.
Before that Fluent lived in Gecko in some form of a glorified javascript library. While it is Fluent’s goal to target the web platform, Firefox UI is inherently different from the web content and benefits from better integration between the DOM and its localization component.
This change allowed us to better integrate localization into the document’s life cycle, but what’s even more important, it allowed us to expose Fluent to documents that usually do not have special privileges and could not access Fluent before.
As for migration, we moved along nicely bumping from 500 to around 800 messages thanks to hard work of a number of students mentored by Jared Wein and Gijs Kruitbosch. The students picked up work on the migration as their Capstone project.
2018 has been much “easier” for the intl module than 2017 was. It’s great to see the how all pieces fit together and for me personally, it enabled me to focus on getting Fluent better integrated into Gecko.
There’s still a lot of work but it now is fully focused on Fluent and localization, while our intl module as a whole goes through a more well earned peaceful period.
Between now and the next status update, I hope to publish a summary post about the last two years of work. Stay tuned!
All of that work was “behind the scenes” and laid the foundation to enable us to bring higher level improvements in the future.
Today, I’m happy to announce that the first of those high-level features has just landed in Firefox Nightly!
Pseudolocalization?
Pseudolocalization is a technology allowing for testing the localizability of software UI. It allows developers to check how the UI they are working on will look like when translated, without having to wait for translations to become available.
It shortens the Test-Driven Development cycle and lowers the burden of creating localizable UI.
Here’s a demo of how it works:
How to turn it on?
At the moment, we don’t have any UI for this feature. You need to create a new preference called intl.l10n.pseudo and set its value to accented for a left-to-right, ~30% longer strategy, or bidi for a right-to-left strategy. (more documentation).
If you test the bidi strategy you also will likely want to switch another preference – intl.uidirection – to 1. This is because right now the directionality of text and layout are not connected. We will improve that in the future.
We’ll be looking into ways to expose this functionality in the UI, and if you have any ideas or suggestions for what you’d like to see, let’s talk!
Nitty-gritty details
Although the feature may seem simple to add, and the actual patch that adds it was less than 100 lines long, it took many years of prototyping and years of development to build the foundation layers to allow for it.
Many of the design principles of Project Fluent combined with the vision shaped by the L10n Drivers Team at Mozilla allowed for dynamic runtime locale switching and declarative UI localization bindings.
Thanks to all of that work, we don’t have to require special builds or increase the bundle size for this feature to work. It comes practically for free and we can extend and fine tune pseudolocalization strategies on fly.
As promised in my previous post, I’d like to do a better job at delivering status updates on Internationalization and Localization technologies at Gecko at shorter intervals than once per year.
In the previous post we covered recent history up to Firefox 58 which got released in January 2018. Since then we finished and shipped Firefox 59 and also finished all major work on Firefox 60, so this post will cover the two.
In 59 we also made severalimprovements to performance of how Fluent operates, all of that while waiting for the stylo-chrome to land in Firefox 60.
In LocaleService, we made another important switch. We replaced old general.useragent.locale and intl.locale.matchOS prefs with a single new pref intl.locale.requested.
This change accomplished several goals:
The name represents the function better. Previously it was pretty confusing for people as to why Gecko doesn’t react immediately when they set the pref. Now it is more clear that this is just a requested locale, and there’s some language negotiation that, depending on available locales, will switch to it or not.
The new pref is optional. Since by default it matches the defaultLocale, we can now skip it and just treat its non-presence as the default mode in which we follow the default locale. That allowed us to remove some code.
The new pref allows us to store locale lists. The new pref is meant to store a comma separated list of requested locales like "fr-CA, fr-FR, en-US", in line with our model of handling locale lists, rather than single locales.
If the pref is defined and the value is empty, we’ll look into OS for the locale to use, making it a replacement for the matchOS pref.
This is important particularly because it took us very long time to unify all uses of the pref, remove it from all around the code and finally be able to switch to the new one which should serve us much better.
Lastly, as we start looking more at aligning our language resources with CLDR, Francesco started sorting out our plural rules differences and language and region names. This is the first step on the path to upstream our work to CLDR and reuse it in place of our custom data.
Although Firefox 60 has not yet been released as of today, the major work cycle on it has finished, and it is currently in the beta channel for stabilization.
In it, we’ve completed another milestone for Fluent migrating not just a couple, but over 100 strings in Firefox Preferences from the old API. This marks the first release where Fluent is actually used to localize a visible portion of Firefox UI!
This is the last symbolic hand-over from the old model to the new, meaning that from that moment the locales registered in L10nRegistry will be used to negotiate language selection for Firefox, and ChromeRegistry becomes a regular customer rather than a provider of the language selection.
We also encountered two interesting bugs – Andre dove deep into ICU to fix `Intl.NumberFormat` breaking on roundings in Persian, and I had to disable some of our bidirectionality features in Fluent due to a bug in Windows API.
With all that work in, we’re slowly settling down the new APIs and finalizing the cleanups and the bulk of work now is going directly into switching away from DTD and .properties to Fluent.
As Firefox 60 is getting ready for its stable release, we’re accelerating the migration of Preferences to Fluent hoping to accomplish it in 61 or 62 release. Once that is completed, we’ll evaluate the experience and make recommendations for the rest of Firefox.
In January 2017, we set the course to get a new localization framework named Fluent into Firefox.
Below is a story of the work performed on the Firefox engine – Gecko – over the last year to make Fluent in Firefox possible. This has been a collaborative effort involving a lot of people from different teams. It’s impossible to document all the work, so keep in mind that the following is just the story of the Gecko refactor, while many other critical pieces were being tackled outside of that range.
Also, the nature of the project does make the following blog post long, text heavy and light on pictures. I apologize for that and hope that the value of the content will offset this inconvenience and make it worth reading.
If you’ve been following Firefox development over the last year, you probably know that we’re hard at work on a major refactor of the browser, codenamed Quantum.
It’s been a very exciting and challenging time with hundreds of engineers bringing to life new concepts and incorporating them into our engine – Gecko. Those refactors, which will culminate in the release of Firefox 57, touch the very foundation of our engine and require massive changes to it.
For several years now, the Localization team at Mozilla has been working on a modern localization framework based on the following set of principles and architectural choices that we consider fundamental for the next generation multilingual UI’s.
Principle 1: Localizers should be in control of translations. The localization framework should be grammar-agnostic, whether it’s about grammatical cases, genders, or tenses. Localizers should be able to use the entire expressive power of their language to author translations which create the best experience for the users.
Principle 2: Language fallback should be robust and graceful. When a translation is missing or broken the user should be presented with a translation into the next best language, given their preferences. There might be more than one fallback language.
Principle 3: Translations should be isolated and asymmetric if needed. The source language of the application should not define structure of the translations (e.g. the lack of pluralization in English should not make it impossible for other languages to use plurals in a given message).
Principle 4: The framework should embrace the Web. Localization should react to changes of the runtime environment (e.g. resizing of the app’s window, change of orientation, incrementation of a number of unread messages) and should add as little overhead for developers as possible.
Exactly one year ago, on April 8th 2014, Staslanded the initial rewrite of l10n.js – the localization framework used in Firefox OS. This set us on the path to enable the vision of a modern localization framework driven by the design principles outlined above.
Since then, we have a dedicated, two person team, working full time on advancing this vision and learning how to improve upon it in the process.
The full year of work has resulted in many important features being developed for the platform, including:
Language packs: Small packages that decouple language resources from the application allowing us to extend language coverage dynamically when users request it, even after the device has been already released on the market.
Pseudo-locales: Programmatically built language resources that emulate different languages allowing developers to test their applications for any multilingual problems before localizers have time to provide translations
Asynchronous l10n: Major shift away from using synchronous API’s for retrieving localizations from JavaScript. This results in clean, condition race free code that is easier to write and maintain. It also sets us on the path to enable runtime language fallback.
Security: While not traditionally big thing in localization, having an open runtime ecosystem of localizations requires us to make sure that translations cannot accidentally or maliciously impact our code and break it.
Error reporting: We’ve made major advancements to help developers and localizers find potential errors early. We reject malformed strings, report missing strings and duplicates, recover from exceptions in our code.
A couple weeks ago we have finalized the work scheduled for Firefox OS 2.2 and begun development for the next major release. The clean and reliable API has given us a good base to start implementing the remaining components of the vision behind L20n in this cycle.
For the current cycle we have scheduled:
DOM Overlays: Ability for a localizer to use HTML syntax in their translations and also provide whole localized DOM Fragments to be merged with developer provided skeletons via a secure algorithm. This increases the system’s security and empowers localizers to provide better translations.
L20n format: One of the last remaining pieces of the puzzle is the new file format that is designed to store localization data like multivariant strings, entities with values and attributes and variant selectors. This will allow us to start introducing new features to the system that are impossible using the current data storing formats.
Lightweight l10n contexts: Together with the whole platform, we want to make a heavier use of the concept of multiple small localization contexts to replace the single-context-per-app approach. It will improve performance and isolation resulting in easier maintenance.
API 3.0: Our current API still contains remaining pieces from the old, synchronous API that we’d like to remove. Together with lightweight contexts and on the path to WebAPI we will want to make sure to organize our events, methods and objects to fit the design of other W3C APIs.
With ever-growing understanding of the environment and how the web stack matures, we are also getting close to start extracting the core of our framework to offer for standardization, and that’s an exciting opportunity to fulfill the vision of both Firefox OS and L20n and bring the modern localization framework to the whole web, making it more multilingual and global.